Practical Introduction to Prometheus Monitoring in 2023

Introduction
Prometheus is a powerful open-source monitoring system that can collect metrics from various sources and store them in a time-series database. It is widely used in the industry to monitor and alert the health of applications, servers, and other infrastructure components.
In this article, we will provide a practical introduction to Prometheus monitoring and cover the essential concepts and features that you need to know to get started.
Architecture
Prometheus follows a pull-based architecture where the (Prometheus) server periodically fetches metrics from the targets that it is configured to monitor. The targets can be various types of applications, services, or servers, and they expose their metrics using a supported protocol, such as HTTP, SNMP, or JMX. Prometheus supports various metric types, such as counters, gauges, histograms, and summaries, and can perform complex aggregations and calculations on them.
Prometheus server stores the collected metrics in a time-series database where a unique combination of metric name, labels, and a timestamp identifies each time-series. The metric name represents the type of metric, such as HTTP requests, CPU usage, or memory usage. The labels provide additional metadata that can be used to differentiate between instances of the same metric, such as server hostname, service name, or version. The timestamp represents the time when the metric was collected.
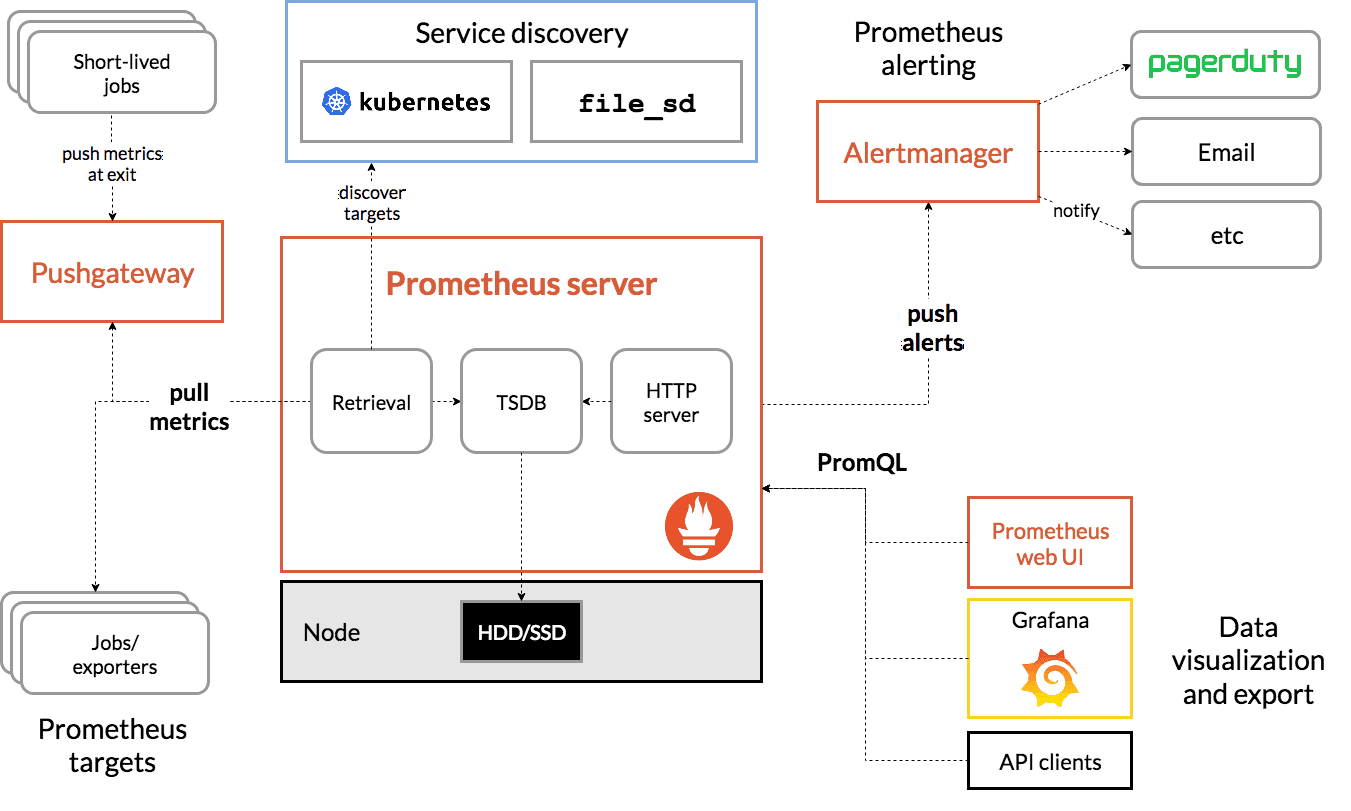
Prometheus provides a built-in query language called PromQL, which allows users to retrieve and aggregate metrics based on various criteria, such as metric name, labels, time range, or mathematical expressions. The query results can be visualized using various tools, such as Grafana, or integrated with alerting systems, such as Alertmanager, to trigger alerts based on predefined rules and thresholds.
Setup and Configuration
To get started with Prometheus monitoring, you need to set up a Prometheus server and configure it to scrape the targets that you want to monitor. Prometheus can be installed on various platforms, such as Linux, macOS, or Windows, and run as a standalone binary or as a Docker container.
Once the Prometheus server is up and running, you need to configure it to scrape the targets by defining a set of scrape jobs in the prometheus.yml configuration file. A scrape job specifies the target endpoints, the interval at which the metrics should be scrapped, and any additional options or filters. For example, the following scrape job configures Prometheus to scrape metrics from a Node.js server that exposes metrics on the default port:
scrape_configs:
- job_name: 'nodejs'
scrape_interval: 5s
static_configs:
- targets: ['localhost:3000']
This configuration tells Prometheus to scrape the metrics every 5 seconds from the target endpoint http://localhost:3000/metrics and store them in the time-series database. The metrics collected from this target will have the default metric prefix nodejs_, and any additional labels can be added using the label_configs option.
PromQL Queries
After configuring Prometheus to scrape your targets, you can start querying the collected metrics using PromQL. PromQL is a flexible and powerful query language that allows you to perform various types of aggregations, filtering, and calculations on the collected metrics.
To get started with PromQL, you can use the Prometheus expression browser, which provides a web-based interface to explore and test PromQL queries. The expression browser allows you to select the metric name, labels, time range, and aggregation functions and displays the query result as a graph or table.
Here are some examples of basic PromQL queries:
up- retrieves the health status of the targets (0 for down, 1 for up).http_request_duration_seconds_count- retrieves the total number of HTTP requests handled by the Node.js server.http_request_duration_seconds_sum- retrieves the response time in seconds of the requests handled by the Node.js server.
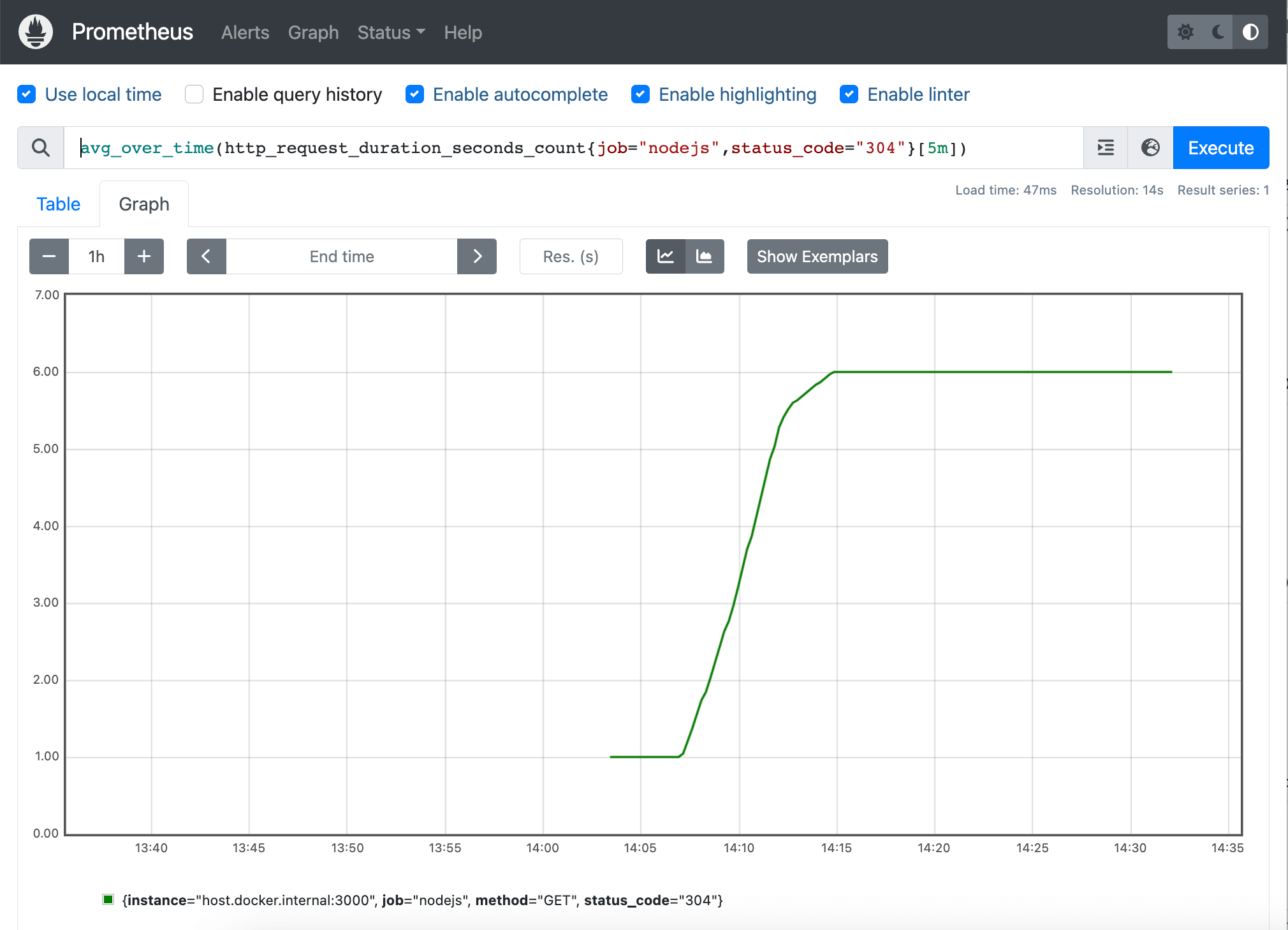
In addition to the basic queries, PromQL supports more advanced features such as vector matching, functions, and operators, that allow you to perform more complex queries. For example, the following query retrieves the average count of requests that responded with 304 status of all instances of the nodejs metric:
avg_over_time(http_request_duration_seconds_count{job="nodejs",status_code="304"}[5m])
This query uses the avg_over_time function to calculate the average number of requests over the last 5 minutes and the [] vector selector to filter the “nodejs” jobs with status code 304.
Alerting
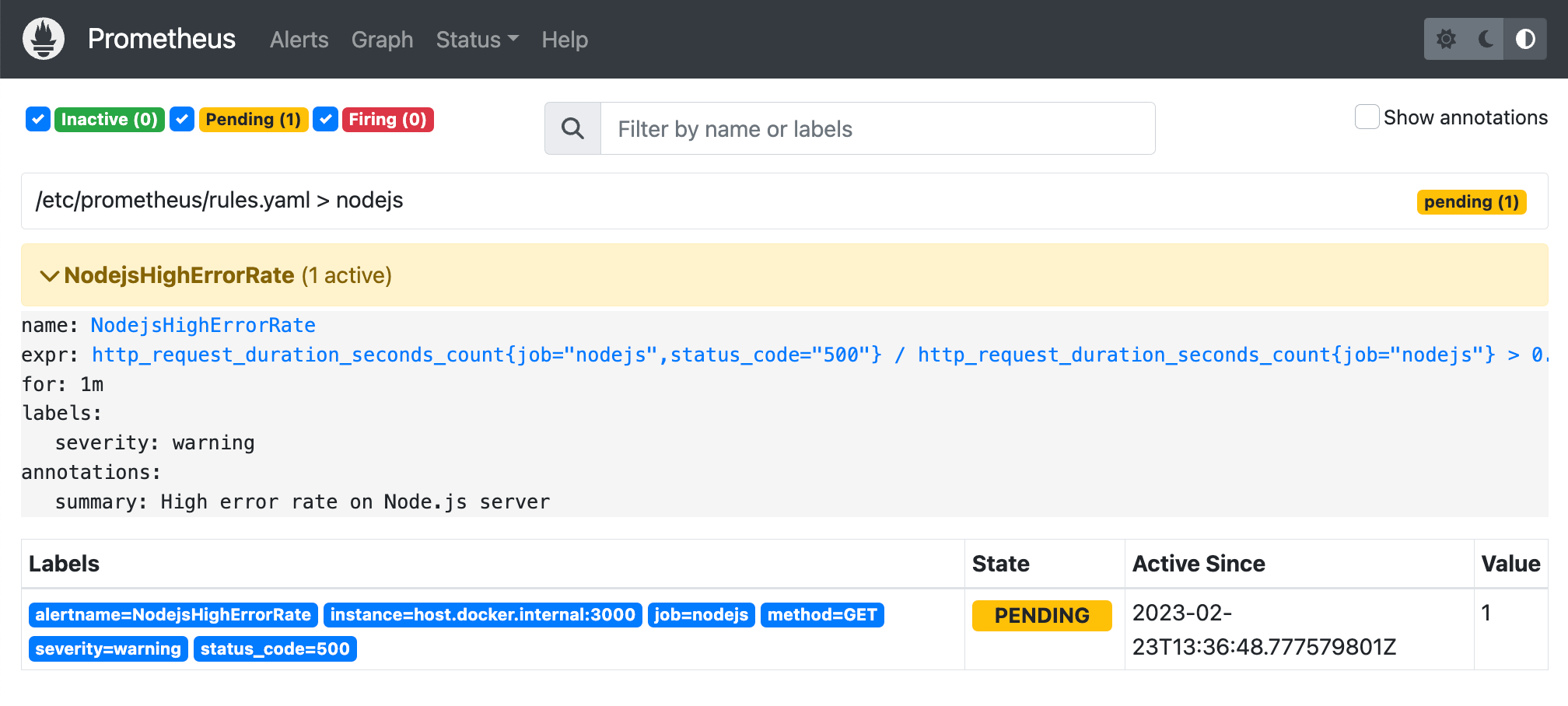
Prometheus supports built-in alerting capabilities that allow you to configure and trigger alerts based on predefined rules and thresholds. To create an alert, you need to define a set of rules in the Prometheus alerting rules file, which specifies the metric name, labels, and the conditions that trigger the alert.
For example, the following alerting rule triggers an alert if the Node.js server CPU usage exceeds 80% for more than 1 minute:
groups:
- name: nodejs
rules:
- alert: NodejsHighErrorRate
expr: http_request_duration_seconds_count{job="nodejs",status_code="500"} / http_request_duration_seconds_count{job="nodejs"} > 0.3
for: 1m
labels:
severity: warning
annotations:
summary: 'High error rate on Node.js server'
This rule uses the expr field to define the condition that triggers the alert, the for field to specify the duration of the condition, and the labels and annotations fields to add additional metadata to the alert.
When the condition is met, Prometheus sends an alert to the Alertmanager, which can then forward the alert to various notification channels, such as email, Slack, or PagerDuty.
Grafana Integration
Prometheus integrates well with Grafana, a popular open-source dashboarding and visualization platform that allows you to create custom dashboards and visualize the collected metrics. To use Grafana with Prometheus, you need to set up a data source that points to your Prometheus server and create a dashboard that displays the desired metrics.
Grafana supports various types of visualizations, such as graphs, tables, gauges, and heatmaps, and allows you to customize the appearance, layout, and behavior of the dashboard. You can also add alerts and annotations to the dashboard to highlight important events and conditions.
We’ll go much deeper into Grafana in the next blog post in this series, so stay tuned!
Conclusion
Prometheus is a powerful and flexible monitoring system that can help you keep track of the health and performance of your applications, servers, and infrastructure components. In this article, we covered the essential concepts and features of Prometheus monitoring, including the architecture, setup and configuration, PromQL queries, alerting, and Grafana integration.
With Prometheus, you can collect, store, and query metrics from various sources, and use the results to gain insights into the behavior and trends of your systems. You can also configure alerts and dashboards that help you detect and respond to issues before they escalate into critical problems.
Whether you are a developer, operator, or site reliability engineer, Prometheus can provide you with the visibility and control that you need to ensure the reliability and availability of your systems. So go ahead and give it a try, and see how it can improve your monitoring and observability workflows.
Eduardo Messuti
Founder and CTO
Eduardo is a software engineer and entrepreneur with a passion for building digital products. He has been working in the tech industry for over 10 years and has experience in a wide range of technologies and industries.
See full bio



Getting started
Ready to streamline incident communication?
Give StatusPal status pages a test drive.
The free 14-day trial requires no credit card and includes all features.